The LHC Will Revolutionize Physics. Can it Revolutionize the Internet Too?
One gigabyte per second? No problem. The LHC computing grid could revolutionize how we handle data over Internet (CERN)
[/caption]
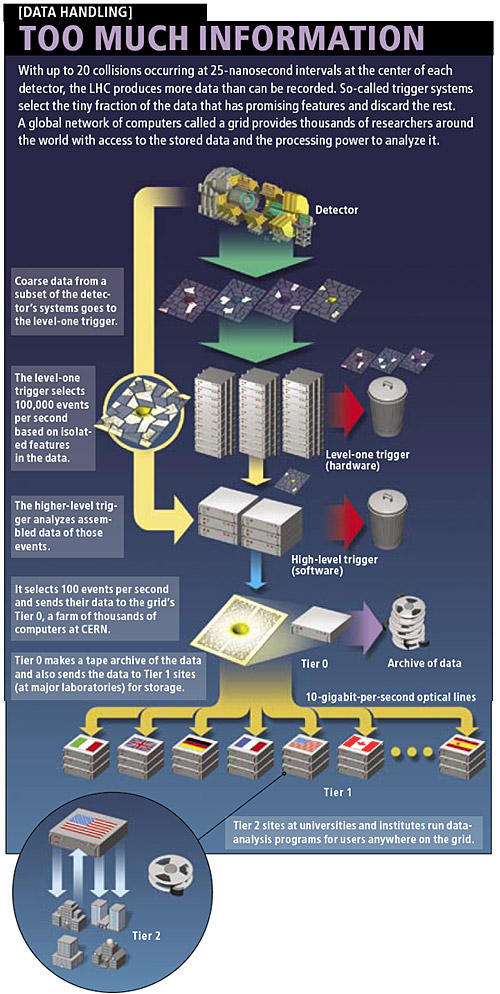
We already know that the Large Hadron Collider (LHC) will be the biggest, most expensive physics experiment ever carried out by mankind. Colliding relativistic particles at energies previously unimaginable (up to the 14 TeV mark by the end of the decade) will generate millions of particles (known and as yet to be discovered), that need to be tracked and characterized by huge particle detectors. This historic experiment will require a massive data collection and storage effort, re-writing the rules of data handling. Every five seconds, LHC collisions will generate the equivalent of a DVD-worth of data, that’s a data production rate of one gigabyte per second. To put this into perspective, an average household computer with a very good connection may be able to download data at a rate of one or two megabytes per second (if you are very lucky! I get 500 kilobytes/second). So, LHC engineers have designed a new kind of data handling method that can store and distribute petabytes (million-gigabytes) of data to LHC collaborators worldwide (without getting old and grey whilst waiting for a download).
In 1990, the European Organization for Nuclear Research (CERN) revolutionized the way in which we live. The previous year, Tim Berners-Lee, a CERN physicist, wrote a proposal for electronic information management. He put forward the idea that information could be transferred easily over the Internet using something called “hypertext.” As time went on Berners-Lee and collaborator Robert Cailliau, a systems engineer also at CERN, pieced together a single information network to help CERN scientists collaborate and share information from their personal computers without having to save it on cumbersome storage devices. Hypertext enabled users to browse and share text via web pages using hyperlinks. Berners-Lee then went on to create a browser-editor and soon realised this new form of communication could be shared by vast numbers of people. By May 1990, the CERN scientists called this new collaborative network the World Wide Web. In fact, CERN was responsible for the world’s first website: http://info.cern.ch/ and an early example of what this site looked like can be found via the World Wide Web Consortium website.
So CERN is no stranger to managing data over the Internet, but the brand new LHC will require special treatment. As highlighted by David Bader, executive director of high performance computing at the Georgia Institute of Technology, the current bandwidth allowed by the Internet is a huge bottleneck, making other forms of data sharing more desirable. “If I look at the LHC and what it’s doing for the future, the one thing that the Web hasn’t been able to do is manage a phenomenal wealth of data,” he said, meaning that it is easier to save large datasets on terabyte hard drives and then send them in the post to collaborators. Although CERN had addressed the collaborative nature of data sharing on the World Wide Web, the data the LHC will generate will easily overload the small bandwidths currently available.
This is why the LHC Computing Grid was designed. The grid handles vast LHC dataset production in tiers, the first (Tier 0) is located on-site at CERN near Geneva, Switzerland. Tier 0 consists of a huge parallel computer network containing 100,000 advanced CPUs that have been set up to immediately store and manage the raw data (1s and 0s of binary code) pumped out by the LHC. It is worth noting at this point, that not all the particle collisions will be detected by the sensors, only a very small fraction can be captured. Although only a comparatively small number of particles may be detected, this still translates into huge output.
Tier 0 manages portions of the data outputted by blasting it through dedicated 10 gigabit-per-second fibre optic lines to 11 Tier 1 sites across North America, Asia and Europe. This allows collaborators such as the Relativistic Heavy Ion Collider (RHIC) at the Brookhaven National Laboratory in New York to analyse data from the ALICE experiment, comparing results from the LHC lead ion collisions with their own heavy ion collision results.
From the Tier 1 international computers, datasets are packaged and sent to 140 Tier 2 computer networks located at universities, laboratories and private companies around the world. It is at this point that scientists will have access to the datasets to perform the conversion from the raw binary code into usable information about particle energies and trajectories.
The tier system is all well and good, but it wouldn’t work without a highly efficient type of software called “middleware.” When trying to access data, the user may want information that is spread throughout the petabytes of data on different servers in different formats. An open-source middleware platform called Globus will have the huge responsibility to gather the required information seamlessly as if that information is already sitting inside the researcher’s computer.
It is this combination of the tier system, fast connection and ingenious software that could be expanded beyond the LHC project. In a world where everything is becoming “on demand,” this kind of technology could make the Internet transparent to the end user. There would be instant access to everything from data produced by experiments on the other side of the planet, to viewing high definition movies without waiting for the download progress bar. Much like Berners-Lee’s invention of HTML, the LHC Computing Grid may revolutionize how we use the Internet.
Sources: Scientific American, CERN
Recent Posts
The Cosmos is Waiting for us to Explore. But we Should Choose our Path Wisely.
If you were Captain of the first USS Enterprise, where would you go!? Humanity is…
The Moon Occults Mars for North America Monday Night, Just Before Opposition 2025
Now is the best time to observe Mars in 2025. Mars from 2014. Credit: Paul…

{kind=link}
Roman’s Telescope and Instruments are Joined
Scheduled for launch in 2027, the Nancy Grace Roman Telescope is slowly being readied for…
SLS Could Launch A Titan Balloon Mission
Few places in the solar system are better suited to a balloon than Titan. The…
How to Deploy and Talk To LEAVES on Venus
We reported before about a NIAC-funded project known as the Lofted Environment and Atmospheric Venues…
NASA is Keeping an Eye on InSight from Space
The InSight Lander arrived on Mars in 2018 to study the planet's interior. Its mission…